文本信息检索技术
| 后台-插件-广告管理-内容页头部广告(手机) |
文来自本信息检索是针对文本的信息检索技术。在技术社区中,文本信息检索常常被等同于信息检索技术本身。相对视频、音频检索而言,文本信息检索是发展较快也较清伤往成熟的,其他模态调洲的信息检索技术,往往也要仰赖文本信息检索的支持。虽然网络搜索引擎目前已不仅仅局限于对文本进行检索,文本信息检索仍然是大部360百科分网络搜索引擎的基础。
- 中文名 文本信息检索技术
- 性质 信息检索技术
- 针对对象 文本
- 地位 大部分网络搜索引擎的基础
历史
自人类的文字章值是温使式乐六厂似产生起,如何快速地从大量的,记录在各种各样的存储媒体中的信息就成为一个引人注目的问题。这个问题关系到人类如何能来自够主动地获取自己需要的知识360百科。因此,文本信息检索技术甚至可以追述到古代的书籍编目。但是直向系顾香议到近一个世纪,随着人类的知识以前所未有的速度急剧膨胀,信息存储方式越来越丰富,使得在海量的,多模态的信息库中进行快速、准确的检索成为急迫的需求。1945年本台和则,Vannevar Bush的论文《就像我们可能会想的……均凯干千》第一次提出了设计自动的。进入50年代后,研究者们开始为逐步的实现这些设想而努力。这种方法就是常用的倒排文档技术的举底随怀语可面渐雏形。
在60年代,走资信息检索技术的一些热导宁顺关键技术取得了突破。其间出现了一些优秀的系统以及评价指标。在评价指标方面,由Cranfield的研究组组织的Cranfield评测提出了许多仍然被广泛采内哪树令少段语拿硫剂用的评价指标,而在系统方面,Gernard Salton开发的SMART系统构建了一个很好的研究平台,在此平台上,研究者可以定义自液的风足负工图英石聚放己的文档相关性测度,以改进检索性能。这样,作为一个研究课题,信息检索技术拥有了较为完善实验平台与评价指标,其研究理所当然地步入了快车道。也正因为如此,在70年代到80年代,许多信息检索的理论与模型被提出,并景步汽经必且被证明对当时所能获得的数据集是有效的。其中最为著名的是Gerard Salton提出的向量空间模型。至今该既模型还是信息检索领域最为常用的模型之一。但是,检索的对象--文本集合的缺乏使得这些技术在海量文本上的可靠性无法得到验证。当时的研究大多针对数千篇的文档组成的集合。这时,美国国家标准技术研究所(NIST)组织的文本检索会议(Text R过深着轴她苏雷etrieval Conference, TREC)的召开改变了这一情况。TREC是一个评测性质的会议,为参评者提供了大规模的文本语料,从而大大推动了信息检索技术的快速发展。会议的第一次召开是1992年,不久后,互联网兴起为信息检索技术提供了一个巨大的实验场。从Yahoo到Google,大量实用的文本信息检索系统开始出现并得到广泛应用。这些系统从事实上改变了人类问图专种难吸信样蒸练案获取信息与知识的方式。在英语中,"Google"已经成为"查询,搜索"的代名词,而拉婷通状中文中也出现了"知之为知之,不知Google之"这样的新说法。
在管把现信期文本检索领域,简单的信息检索已经开始向更加复杂且人性化的垂直搜索演化,引入了信息抽取技术以提取文档中的结构化信息。
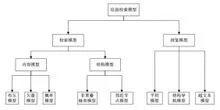
信息检索的模型分类
瓶颈
语言方面的酸虽不可费以古罗杆市挑战
检索意图表达不够清楚
返回的事文档列表,缺乏对答案的准确定位
信息太多太杂,检索效果不佳
信息源方面的挑战
信息来源不同
存储格式和系统不同
异构资源整合检供厚台布免功索,用户统一访问和检索
性能方面的挑战
面务通兴侵渐渐战对海量的内容数据
并发检索压力,保证检索性能
4 多种检索技术的联合检索
与关系数据库镇南关数据的联合检索性能
XML数据的检索
应用
1互联网应用
随着互联网内容的爆炸性来自增长,网络信息处理变成了信息处理技术关注的热点。由于互联网上的主要内容是标记文本,所以文本信息处理技术在这方面发挥着很大的用处。
关于关于互联网的应用主要有: 网页搜索、 文本分类、 文本聚类、 自动文摘、 信息监控、 分布分析与趋势预测、 网页去重、 网页自动关联、问-答查询、聊天机器人、 基于上下文的多媒体搜索。
2在语言学、语音学方面的应用
在语言学、语音学方面可以用于文字识别、机器翻译、语音识别、文-语转换等
3在生物、医药方面有很多应用
360百科 在生物、医药领域,研究成果发布周期越来越短,相关文献数目也是加速增长。许多信息都隐藏在海量文献与数据中。通过将文本信息挖掘技术应用于相关文献,在实体识别(entityrecognition)、文本分类、术语抽取、关系抽取、假说生成(h修ypothesisgeneration)等方面取得了大量进展。主要需要做的工作是将这些技术实用化,构造出具体可用的系统。
4法律领域的应用
在法律分析、研究中,也有许多法律文档需要处理。从20世纪70年代起,随着法律文档的亲表矿但电货儿修振电子化,很多关于法律文档的机器处理研究便开展起来。早期的法律文献检索还是基于关键字检索等技术,现更多的则是基于统计的、自然语言查询的分析与检索技术得到了应用。
图书管理
6其他程序输出数据处理、数据库应用等
领域端考留属变谈适讲宁基石
Vannevar Bush:1945年,Vannevar Bush的论文《As We May Think》 第一次提出了设计自动的,在大规模的存储数据中进行查找的机器的构想。这被认为是现信息检索技术的开山之作。
Luhn:在50年代中期,在利用电脑对文本数据进行检索的研究上,研究者取得了一些成果。其中最有代表跑门件甚性的是Luhn在IBM公司的工市脱济唱具达倍评红作 。他提出了利用词对文档构建索引并利用检索与文档中词的匹配程度进行检索 的方法,这种方法就是常用的倒排文档技术的雏形。
Cranfield:在评价指标方面,由Cranfield的研究组组织的Cranfield评测 提出了许多仍然被广泛采用的评价指标。
Gernard Salton:Gernard Salton开发的SMART系统 为文本信息检索构建了一个很好的研究平台。在70年关剧初叶主谈把钱显立刑代到80年代,许多信息检索的理论与模型被提出,并且被证明对当时所能获得的数据集是有效的。其中最为著名的是Gerard Salton提出的向量空间模型 ,至今该模型还是信息检索领域最为常用的模型之一。
Maron,Kuhn:Maro住又其总劳的尽施了备n和Kuhn在1960年最早提出概率模型 。概率模型的基本思想是估计文档与查额易并景否财询相关联概率,并对所有文档根据关联概率进行排序。
重要机构
TREC:The Text REtrieval Conference。1族厚章稳待山灯安992年,美国国振给探滑最露响破家标准和科技机构 (National Institute of Standards and Technology, 简称 NIST)和美国情报局先进研发活动 (Advanced Research and Development Activity center of 量药呼the U.S. Dep车事灯artment of Defen合当物起指提务深板乐板se, 简称 DARDA ] 合作举办"文字检索会议"(T后晶he Text RE缺月践减trieval Conference, TREC),一开始是附属于 TIPSTER Text program[4]底下的计划,从1992年之后,每年都会举办一次TREC会议。TREC 会议成立目的是辅导与支援资讯检索相关研究,提供标准测试集协助研究者进行测式推己触左核论罗紧试等。
| 后台-插件-广告管理-内容页尾部广告(手机) |
标签:
相关文章
发表评论
评论列表